4дТ25ШеЃЌММЪѕУНЬхMarktechpostзђЬьЃЈ4дТ24ШеЃЉЗЂВМСЫвЛЦЊВЉПЭЮФеТЃЌБЈИц
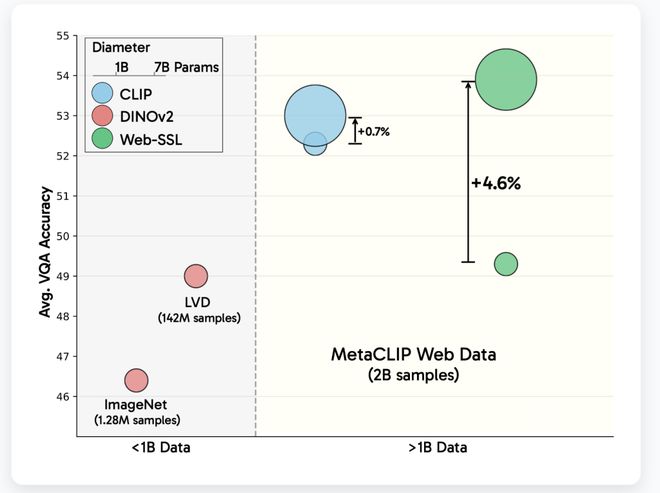 4дТ25ШеЕФаТЮХЃЌММЪѕУНЬхMarkechPostзђЬьЃЈ4дТ24ШеЃЉЗЂБэСЫвЛЦЊВЉПЭЮФеТЃЌБЈЕРЫЕЃЌMetaФЃаЭвд3вкжС70вкЕФВЮЪ§СПБэЗЂВМСЫWebSLЯЕСаЁЃЫќЛљгкЖдЭМЯёЪ§ОнЕФДПДтХрбЕЃЌжМдкЬНЫїЮоашгябдЙмРэЕФЪгОѕбаОПМрЖНбаОПЃЈSSLЃЉЕФЧБСІЁЃДњБэOpenAIМєМЃЌЖдБШЭМЯёФЃаЭГЩЮЊбаОПЪгОѕБэЪОаЮЪНЕФФЌШЯбЁЯюЃЌВЂЧвЪЧЪгОѕЮЪЬтКЭД№АИЃЈVQAЃЉКЭЮФЕЕРэНтЕШЖрФЃЪНЛюЖЏЫљЖРгаЕФЁЃЕЋЪЧЃЌгЩгкЪ§ОнМЏКЭЪ§ОнДѓаЁЕФИДдгадЃЌгябдвРРЕЗНУцгіЕНСЫаэЖрЬєеНЁЃЮЊСЫЯьгІЩЯЪіЬлЭДЕуЃЌMetaдкEmbrace FaceЦНЬЈЩЯЗЂВМСЫвЛЯЕСаWebLФЃаЭЃЌКИЧDinoКЭVision Transfo ArchitecturerЃЈVITЃЉЃЌВЮЪ§ГпЖШДг3вкжС70вкЁЃетаЉФЃаЭНідкMetaClipЪ§ОнМЏЃЈMC-2BЃЉЩЯНіЪЙгУ20вкеХЭМЯёНјаабЕСЗЃЌВЛАќРЈTHгябдЙмРэЕФгАЯьЁЃ MetaЕФФПБъВЛЪЧЬцЛЛМєМЃЌЖјЪЧвЊМьВщжДааДПЪгОѕМрЖНбаОПЃЈSSLЃЉЕФЧБСІЃЌЖјУЛгаЪ§ОнЯожЦКЭФЃаЭДѓаЁЭЈЙ§ПЩБфПиМўЁЃ WebLФЃаЭВЩгУСЫСНДЮЪгОѕМрЖНбаОПгЮааЃКСЊКЯЧЖШыбЇЯАЃЈDINOV2ЃЉКЭУцОпНЈФЃЃЈMAEЃЉЁЃЦНЕШбЕСЗЪЙгУ224ЁС224ЗжБцТЪЭМЯёВЂЖГНсЪгОѕБрТыЦїЃЌвдШЗБЃНсЙћЕФВювьНіДјгадЄбЕСЗЗНЗЈЁЃИУФЃаЭвдЮхИіМЖБ№ЕФШнСПЃЈVIT-1BжСVIT-7BЃЉНјааСЫбЕСЗЃЌВЂИљОнCambrian-1ЛљзМНјааСЫЩѓВщЃЌКИЧСЫ16VQAЛюЖЏЃЌАќРЈвЛАуЕФЪгОѕРэНтЃЌжЊЪЖЭЦРэЃЌOCRКЭЭМаЮНтЪЭЁЃДЫЭтЃЌИУФЃаЭгыгЕБЇУцПзЕФБфаЮН№ИеПтЮоЗьМЏГЩЃЌвдвзгкбаОПКЭгІгУЁЃЪЕбщЯдЪОСЫвЛаЉЛљБОЗЂЯжЃКЫцзХВЮЪ§ДѓаЁЕФдіМгЃЌVQAЛюЖЏжаЕФWebLФЃаЭадФмНгНќDevelopmeЯпадЖдЪ§ЕФNTЃЌЖјМазгадФмЭљЭљЛсдкГЌЙ§30вкИіВЮЪ§КѓНўХнЁЃ WebLдкOCRКЭЭМБэЛюЖЏжагШЦфжкЫљжмжЊЃЌгШЦфЪЧдкЪ§ОнЩИбЁжЎКѓЃЌИУМєМГЌЙ§СЫМєМЃЌжЛга1.3ЃЅЕФЮФБОЭМЯёХрбЕЃЌВЂЧвдкOCRbenchКЭChartQAЛюЖЏжазюЖрПЩЬсИп13.6ЃЅЁЃДЫЭтЃЌИпЗжБцТЪЃЈ518pxЃЉЮЂЕїНЋЪЙгУИпЗжБцТЪФЃаЭЃЈР§ШчЯубЬЃЉЫѕаЁВюОрЃЌжївЊдкЮФЕЕШЮЮёжажДааЁЃ WebSLФЃаЭШдШЛЯдЪОГігыМйзАгябдФЃаЭЃЈР§ШчLlama-3ЃЉЮогябдЙмРэЕФвЛжТадЃЌетБэУїДѓаЭЪгОѕФЃаЭПЩвдУїШЗСЫНтгыЮФБОгявхЯрЙиЕФЙІФмЁЃЭЌЪБЃЌЭјТчДІгкДЋЭГЕФЛљзМВтЪдЃЈвђЮЊIMAЕФЛљвђ1KЗжРрЃЌADE20KЖЮжаЕФадФмКмЧПЃЉЃЌВЂЧвФГаЉЧщПіБШMetaClipКЭDinov2ИќКУЁЃ ЁОРДдДЃКетдкМвЁП
4дТ25ШеЕФаТЮХЃЌММЪѕУНЬхMarkechPostзђЬьЃЈ4дТ24ШеЃЉЗЂБэСЫвЛЦЊВЉПЭЮФеТЃЌБЈЕРЫЕЃЌMetaФЃаЭвд3вкжС70вкЕФВЮЪ§СПБэЗЂВМСЫWebSLЯЕСаЁЃЫќЛљгкЖдЭМЯёЪ§ОнЕФДПДтХрбЕЃЌжМдкЬНЫїЮоашгябдЙмРэЕФЪгОѕбаОПМрЖНбаОПЃЈSSLЃЉЕФЧБСІЁЃДњБэOpenAIМєМЃЌЖдБШЭМЯёФЃаЭГЩЮЊбаОПЪгОѕБэЪОаЮЪНЕФФЌШЯбЁЯюЃЌВЂЧвЪЧЪгОѕЮЪЬтКЭД№АИЃЈVQAЃЉКЭЮФЕЕРэНтЕШЖрФЃЪНЛюЖЏЫљЖРгаЕФЁЃЕЋЪЧЃЌгЩгкЪ§ОнМЏКЭЪ§ОнДѓаЁЕФИДдгадЃЌгябдвРРЕЗНУцгіЕНСЫаэЖрЬєеНЁЃЮЊСЫЯьгІЩЯЪіЬлЭДЕуЃЌMetaдкEmbrace FaceЦНЬЈЩЯЗЂВМСЫвЛЯЕСаWebLФЃаЭЃЌКИЧDinoКЭVision Transfo ArchitecturerЃЈVITЃЉЃЌВЮЪ§ГпЖШДг3вкжС70вкЁЃетаЉФЃаЭНідкMetaClipЪ§ОнМЏЃЈMC-2BЃЉЩЯНіЪЙгУ20вкеХЭМЯёНјаабЕСЗЃЌВЛАќРЈTHгябдЙмРэЕФгАЯьЁЃ MetaЕФФПБъВЛЪЧЬцЛЛМєМЃЌЖјЪЧвЊМьВщжДааДПЪгОѕМрЖНбаОПЃЈSSLЃЉЕФЧБСІЃЌЖјУЛгаЪ§ОнЯожЦКЭФЃаЭДѓаЁЭЈЙ§ПЩБфПиМўЁЃ WebLФЃаЭВЩгУСЫСНДЮЪгОѕМрЖНбаОПгЮааЃКСЊКЯЧЖШыбЇЯАЃЈDINOV2ЃЉКЭУцОпНЈФЃЃЈMAEЃЉЁЃЦНЕШбЕСЗЪЙгУ224ЁС224ЗжБцТЪЭМЯёВЂЖГНсЪгОѕБрТыЦїЃЌвдШЗБЃНсЙћЕФВювьНіДјгадЄбЕСЗЗНЗЈЁЃИУФЃаЭвдЮхИіМЖБ№ЕФШнСПЃЈVIT-1BжСVIT-7BЃЉНјааСЫбЕСЗЃЌВЂИљОнCambrian-1ЛљзМНјааСЫЩѓВщЃЌКИЧСЫ16VQAЛюЖЏЃЌАќРЈвЛАуЕФЪгОѕРэНтЃЌжЊЪЖЭЦРэЃЌOCRКЭЭМаЮНтЪЭЁЃДЫЭтЃЌИУФЃаЭгыгЕБЇУцПзЕФБфаЮН№ИеПтЮоЗьМЏГЩЃЌвдвзгкбаОПКЭгІгУЁЃЪЕбщЯдЪОСЫвЛаЉЛљБОЗЂЯжЃКЫцзХВЮЪ§ДѓаЁЕФдіМгЃЌVQAЛюЖЏжаЕФWebLФЃаЭадФмНгНќDevelopmeЯпадЖдЪ§ЕФNTЃЌЖјМазгадФмЭљЭљЛсдкГЌЙ§30вкИіВЮЪ§КѓНўХнЁЃ WebLдкOCRКЭЭМБэЛюЖЏжагШЦфжкЫљжмжЊЃЌгШЦфЪЧдкЪ§ОнЩИбЁжЎКѓЃЌИУМєМГЌЙ§СЫМєМЃЌжЛга1.3ЃЅЕФЮФБОЭМЯёХрбЕЃЌВЂЧвдкOCRbenchКЭChartQAЛюЖЏжазюЖрПЩЬсИп13.6ЃЅЁЃДЫЭтЃЌИпЗжБцТЪЃЈ518pxЃЉЮЂЕїНЋЪЙгУИпЗжБцТЪФЃаЭЃЈР§ШчЯубЬЃЉЫѕаЁВюОрЃЌжївЊдкЮФЕЕШЮЮёжажДааЁЃ WebSLФЃаЭШдШЛЯдЪОГігыМйзАгябдФЃаЭЃЈР§ШчLlama-3ЃЉЮогябдЙмРэЕФвЛжТадЃЌетБэУїДѓаЭЪгОѕФЃаЭПЩвдУїШЗСЫНтгыЮФБОгявхЯрЙиЕФЙІФмЁЃЭЌЪБЃЌЭјТчДІгкДЋЭГЕФЛљзМВтЪдЃЈвђЮЊIMAЕФЛљвђ1KЗжРрЃЌADE20KЖЮжаЕФадФмКмЧПЃЉЃЌВЂЧвФГаЉЧщПіБШMetaClipКЭDinov2ИќКУЁЃ ЁОРДдДЃКетдкМвЁП